
HighByte Intelligence Hub 3.0 mit Unified Namespace

Die neueste Version des HighByte Intelligence Hub stellt UNS (Unified Namespace) als vorkonfiguriertes Paket für den Einsatz in Industriebetrieben zur Verfügung. Damit ist die Software genau auf die aktuellen Marktbedürfnisse zugeschnitten.
DataOps-Lösungen, welche die Herausforderungen des Datenmanagements lösen, werden immer stärker nachgefragt! Die enormen Datenmengen, die verarbeitet, kontextualisiert und skaliert werden müssen, verursachen einen hohen Zeitaufwand, der die Entwicklung bremst.
Statt mit der Analyse von Daten verbringen Datenanalysten einen Grossteil ihrer Zeit mit deren Bereinigung. Mit HighByte Intelligence Hub 3.0 wird sich dies nun ändern.
HighByte Intelligence Hub Version 3.0 ist jetzt verfügbar!
HighByte hat mit der neuesten Version von Intelligence Hub hervorragende Arbeit geleistet. Die Version 3.0 Beta wurde von 55 Beta-Testern in 13 verschiedenen Ländern in einer operativen Umgebung getestet und die Rückmeldungen sind beeindruckend.
Mit den einzigartigen Funktionen von Intelligence Hub verbinden wir MQTT Sparkplug- und OPC UA-Quellen nahtlos.Die Verbindungen sind bidirektional, dynamisch, und das Verbinden der Quellnomenklatur mit einem größeren Namensraum erfolgt mit geringem Aufwand. Früher haben wir jeden Punkt separat definiert, jetzt passiert es automatisch. Tord van Delft, Projektingenieur, Goodtech
In dem Artikel Why HighByte Intelligence Hub version 3.0 is a step change for Industrial DataOps erzählt Torey Penrod-Cambra von HighByte anhand praktischer Beispiele die Vorzüge der neuen Version.
Alle neuen Funktionen, die mit HighByte Intelligence Hub 3.0 eingeführt wurden, sind auf der Seite von HighByte aufgelistet: Release Notes
Die wichtigsten neuen Features in HighByte Intelligence Hub 3.0
Als erstes industrielles DataOps-Tool verbindet der HighByte Intelligence Hub von Anfang an Daten aus IT- und OT-Systemen in einer für beide Seiten verständlichen Form. Die Version 3.0 bietet neue Funktionen, die auf die sich ändernden Herausforderungen reagieren und den Benutzern noch grössere Zeit- und Kosteneinsparungen ermöglichen.
Es reicht nicht immer aus, Daten zu sammeln, zu modellieren und zu versenden – es braucht modernere Methoden, um mit komplexen Daten umgehen zu können. Im Folgenden stellen wir Ihnen die beiden wichtigsten Features der neuen Version vor: MQTT Broker und Data Pipeline.
MQTT-Broker
Diese Funktion bringt die MQTT-basierte Kommunikation direkt auf HighByte. Dadurch ist es möglich, einen einheitlichen Namensraum zu schaffen. Jedes System, das Daten anfordert, erhält diese nun von der Schnittstelle in immer derselben kontextabhängigen und einheitlichen Form.
Data Pipeline
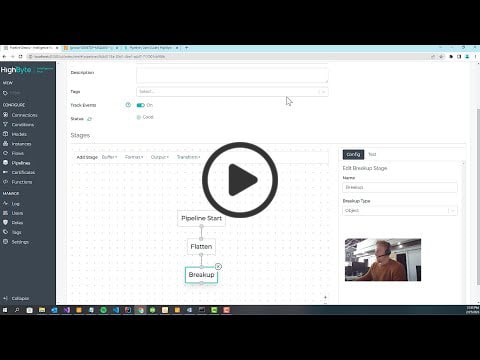
Die Data Pipeline wurde entwickelt, um den Umgang mit komplexen Daten zu erleichtern. Sie ermöglicht die einfache und effiziente Visualisierung und Verwaltung von Datenflüssen auf individueller Basis. Dazu bietet sie eine Vielzahl von Funktionen, wie z.B. das Editieren und Puffern von Daten.
Im folgenden Video demonstriert Aron Semle, Chief Technology Officer von HighByte, die neue Pipeline-Funktion anhand eines Anwendungsfalls für die Protokolltransformation. Dafür wird die Hierarchiestruktur aus OPC UA exportiert und in Sparkplug importiert. Lernen Sie, wie Sie die Pipeline-Funktion zum Filtern, Glätten und Hierarchisieren von Daten von Sparkplug und MQTT über JSON verwenden können.
Möchten Sie mehr wissen?
Sie haben Fragen oder möchten sichergehen,
dass HighByte Ihre speziellen Anforderungen
erfüllen kann?








